
"해시"
데이터를 다른 형태로 변환해주는 함수
이론
해시함수(hash function)는 데이터를 다른 형태로 변환해주는 함수를 뜻합니다.
해시 함수에 의해 얻어지는 값은 해시값, 해시 코드, 해시 체크섬 또는 간단하게 "해시"라고 합니다.
해시 함수만 사용했을 때보다 자료구조와 연결하면 강력한 성능을 발휘하게 됩니다!
많이 쓰는 자료구조로는 해시 테이블 (hash table)을 들 수 있습니다.
해시 테이블은 데이터의 삽입, 삭제, 탐색을 지원하는 자료구조입니다.
해시 테이블의 삽입, 삭제, 탐색은 평균적으로 O(1), 최악의 경우 O(n) 시간이 소요됩니다.
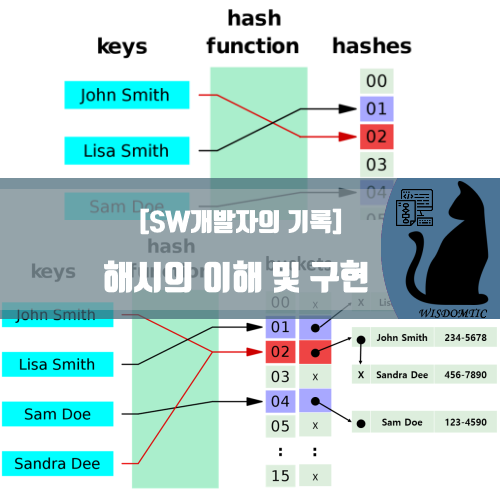
크기가 S인 해시 테이블의 구조를 보면, 0~ S-1 까지 번호가 붙은 버킷이 S개 존재합니다.
데이터 A를 삽입/삭제/탐색할 때에는
해시함수에 데이터 A를 넣어서 나온 값 h(A)을 찾아서, h(A) 번 버킷에 A를 삽입/삭제/탐색하게 됩니다.

위의 예시의 경우,
h("John Smith") = 2, h("Lisa Smith") = 1, h("Sam Doe") = 4입니다.
그런데 다른 데이터에 대해 해시 함수의 값이 같게 나오는 경우가 발생할 수 있는데,
이를 "충돌 (Collision)"이라고 합니다.

해시 테이블에서는 충돌이 일어날 경우, 데이터들을 연결 리스트(linked list)로 저장합니다.
연결 리스트가 가지는 특성에 따라, 해시 테이블에서의 연산은 충돌 횟수만큼 시간이 걸리기 때문에
충돌의 횟수가 적을수록 좋은 해시 함수라고 평가됩니다.
해시 함수가 충분히 좋은 경우, 충돌 횟수는 O(1)로 수렴하게 되고,
반대로 해시 함수의 성능이 좋지 않은 경우, 연산 한 번에 O(n)의 시간이 걸리게 될 수도 있습니다.
코드
#include <stdio.h>
//DATA 형태 정의
struct DATA {
int a1, a2, a3; // data의 type
// 생성자 정의
DATA() {}
DATA(int a1, int a2, int a3):a1(a1), a2(a2), a3(a3) {}
//비교연산자 정의
bool operator == (const DATA& A) const {
return a1 == A.a1 && a2 == A.a2 && a3 == A.a3;
}
bool operator != (const DATA& A) const {
return a1 != A.a1 || a2 != A.a2 || a3 != A.a3;
}
};
//hash
class hash_table {
public:
const static int SIZE = 10000;
//노드 선언
struct NODE {
DATA value;
NODE* next; //연결리스트로 지원하기 위한 next 원소의 위치
NODE(){}
NODE(DATA value, NODE* next):value(value), next(next) {}
};
//총사이즈 만큼의 버킷 존재
NODE* table[SIZE];
hash_table() {
for (int i = 0; i < SIZE; i++) table[i] = NULL;
}
//해쉬 함수 정의 -> 성능이 좋도록 디자인 해야 함
int hash(DATA& A) {
return (A.a1 + A.a2 + A.a3) % SIZE;
}
//삽입 연산 -> 새로운 노드를 기존 노드 앞에 삽입
void insert(DATA key) {
int index = hash(key);
table[index] = new NODE(key, table[index]);
}
//삭제 연산 -> iterator로 찾은 노드의 next를 prev의 next에 연결해서 가운데 노드를 삭제
void remove(DATA key) {
int index = hash(key);
NODE *prev = NULL, *it = table[index];
while (it != NULL && it->value != key) {
prev = it;
it = it->next;
}
if (it == NULL) return; //not found
if (prev == NULL) {
table[index] = table[index]->next;
}
else {
prev->next = it->next;
}
}
//탐색 연산
bool search(DATA key) {
int index = hash(key);
NODE* it = table[index];
while (it != NULL) {
if (it->value == key) return true;
it = it->next;
}
return false;
}
};'SW 공부 > Algorithm' 카테고리의 다른 글
| [List 자료구조] Array List, Linked List (2) | 2021.04.23 |
|---|---|
| [DFS & BFS] 깊이 우선 탐색과 너비 우선 탐색의 이해 및 구현 (2) | 2021.01.12 |
| [허프만 코드] Huffman Code의 이해 및 구현 (0) | 2020.12.19 |
| [파라메트릭 서치] Parametric Search의 이해 및 구현 (2) | 2020.12.16 |




댓글