

"허프만 코드"
문자 빈도 수를 이용해 통계적으로 압축하는 알고리즘
이론
허프만 코드는 압축 알고리즘 중 하나로, 입력 데이터를 더 적은 용량으로 만드는 것입니다.
허프만 코드의 요점은 자주 나오는 문자에는 짧은 비트를, 조금 나오는 문자에는 긴 비트를 할당하는 것입니다.
예를 들어 AABBAC라는 문자열을 살펴보면, 각 문자의 빈도수는 아래와 같습니다.
A : 3번 B : 2번 C : 1번
이에 따라, 가장 자주 나오는 문자 A에는 0, B는 10, C는 11을 부여하면 001010011로 나타내어집니다.
원래의 문자열 AABBAC는 6글자 이므로 48 bit가 사용되지만,
압축된 코드 001010011은 9bit만 사용되어 표현할 수 있습니다.
< 허프만 코드의 작동 방법 - 인코딩 과정 >
1. 주어진 텍스트에서 각 문자의 출현 빈도수를 계산합니다.
2. 각 문자의 빈도수를 이용하여 이진 트리를 생성하여 -> 각 문자에 이진 코드를 부여합니다.
1) 빈도수가 가장 낮은 두 문자 (또는 그룹) 선택 ex) priority_queue : pop min vaule
2) 고른 두개의 문자( 또는 그룹)를 자식노드로 하는 새로운 그룹(부모노드)을 생성합니다.
3) 이 때 새로운 그룹(부모노드)의 빈도수는 묶은 두 그룹(자식노드) 빈도수의 합이다.
4) 묶어줄 때, 좌우의 두 간선은 각각 0 과 1을 배정하는데 이를 이진 트리의 left, right 자식으로 표현한다.
5) 남은 그룹이 2개 이상이면 1)번부터 반복한다.
3. 주어진 텍스트의 각 문자를 코드로 변환하여 압축된 텍스트를 생성합니다.
각 문자에 부여된 이진 코드가 다른 문자에 부여된 이진 코드의 접두부가 되지 않는 코드가 됩니다.
이와 같은 방식"prefix code" 으로 이진코드를 만들어야,
인코딩(암호화) 한 코드를 디코딩(복호화)할 때 문제가 발생하지 않습니다!
허프만트리 예시
문자열DML 빈도수가 다음과 같을 때, A : 3, B : 4, C : 5, D : 4, E :8
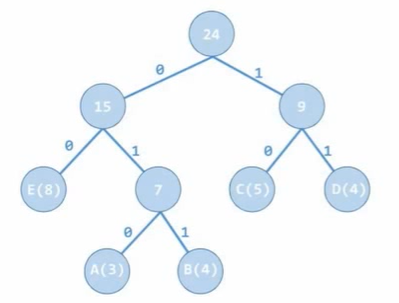
각 문자를 이진화 시킨 코드는 아래와 같이 표현됩니다.
A: 010, B: 011, C: 10, D: 11. E : 00
코드
#include <stdio.h>
#include <queue>
#include <functional>
#include <stdlib.h>
using namespace std;
typedef struct Node {
char c; //0이면 그룹
int fre; //빈도수
Node* left;
Node* right;
bool operator > (const Node A) const {
return fre > A.fre;
}
} Node, *PNode;
int N;
priority_queue<Node, vector<Node>, greater<Node> > heap;
char code[100];
void print_code(PNode node, int size) {
if (node->c) {
code[size] = 0; //문자 발견-> 이진코드 종료문자
printf("%c :%s\n", node->c, code);
}
else {
if (node->left) {
code[size] = '0'; //이진 코드 0
print_code(node->left, size + 1);
}
if (node->right) {
code[size] = '1'; //이진 코드 1
print_code(node->right, size + 1);
}
}
}
int main() {
int i, j;
char c;
int fre;
Node node = {'0',0,0,0};
PNode parent, left, right;
scanf("%d", &N);
for (int i = 1; i <= N; i++) {
scanf("\n%c %d", node.c, node.fre);
heap.push(node);
}
for (int i = 1; i < N; i++) {
left = (PNode)malloc(sizeof(Node));
right = (PNode)malloc(sizeof(Node));
parent = (PNode)malloc(sizeof(Node));
// 빈도수가 가작 작은 문자 2개 선택
*left = heap.top(); heap.pop();
*right = heap.top(); heap.pop();
//새 노드를 생성하여 두 자식 노드로 지정
parent->left = left;
parent->right = right;
//새 노드의 빈도수 = 자식 노드의 빈도수
parent->fre = left->fre + right->fre;
parent->c = 0; // 그룹
heap.push(*parent); //새 그룹을 힙에 삽입
}
print_code(&heap.top(), 0);
return 0;
}'SW 공부 > Algorithm' 카테고리의 다른 글
| [List 자료구조] Array List, Linked List (2) | 2021.04.23 |
|---|---|
| [DFS & BFS] 깊이 우선 탐색과 너비 우선 탐색의 이해 및 구현 (2) | 2021.01.12 |
| [파라메트릭 서치] Parametric Search의 이해 및 구현 (2) | 2020.12.16 |
| [Hash 알고리즘] 해시의 이해 및 구현 (2) | 2020.12.16 |




댓글